Light camera traps for monitoring of nocturnal pollinators
Description of the tool
The UKCEH Automated Monitoring of Insects (UKCEH AMI-trap) is an autonomous light-trap system developed by UKCEH to support large-scale, standardised insect monitoring. It integrates UV and LED light sources with a high-resolution camera and motion-detection software to capture images of nocturnal insects attracted to the trap. The system is controlled by a Raspberry Pi computer, with on-board data storage and power management that allows fully autonomous operation in the field.
Benefits of using the technology
Provides standardised, continuous monitoring of nocturnal insect populations with minimal need for human intervention.
Captures high-quality images that can be used for species identification, enabling the creation of rich, verifiable biodiversity datasets.
Can be deployed in remote or challenging environments thanks to its robust, weather-resistant design.
Fully autonomous operation, including programmable timers and watchdog systems for reliable long-term deployments.
Designed to be modular and adaptable, allowing integration with different power supplies (mains, battery, solar) and supporting flexible field protocols.
Supports biodiversity research, conservation planning, and policy by enabling scalable insect monitoring across multiple sites.
Target users
The AMI-trap is designed for:
Research organisations and universities studying insect populations, biodiversity change, or ecosystem health.
Conservation agencies and NGOs monitoring threatened species or habitats.
Environmental regulators and government bodies responsible for biodiversity assessments.
Agricultural and land management organisations tracking pest and pollinator activity.
Citizen science networks and monitoring schemes looking for scalable, standardised insect recording tools.
Read more
Insect camera traps for monitoring of diurnal pollinators
Description of the tool
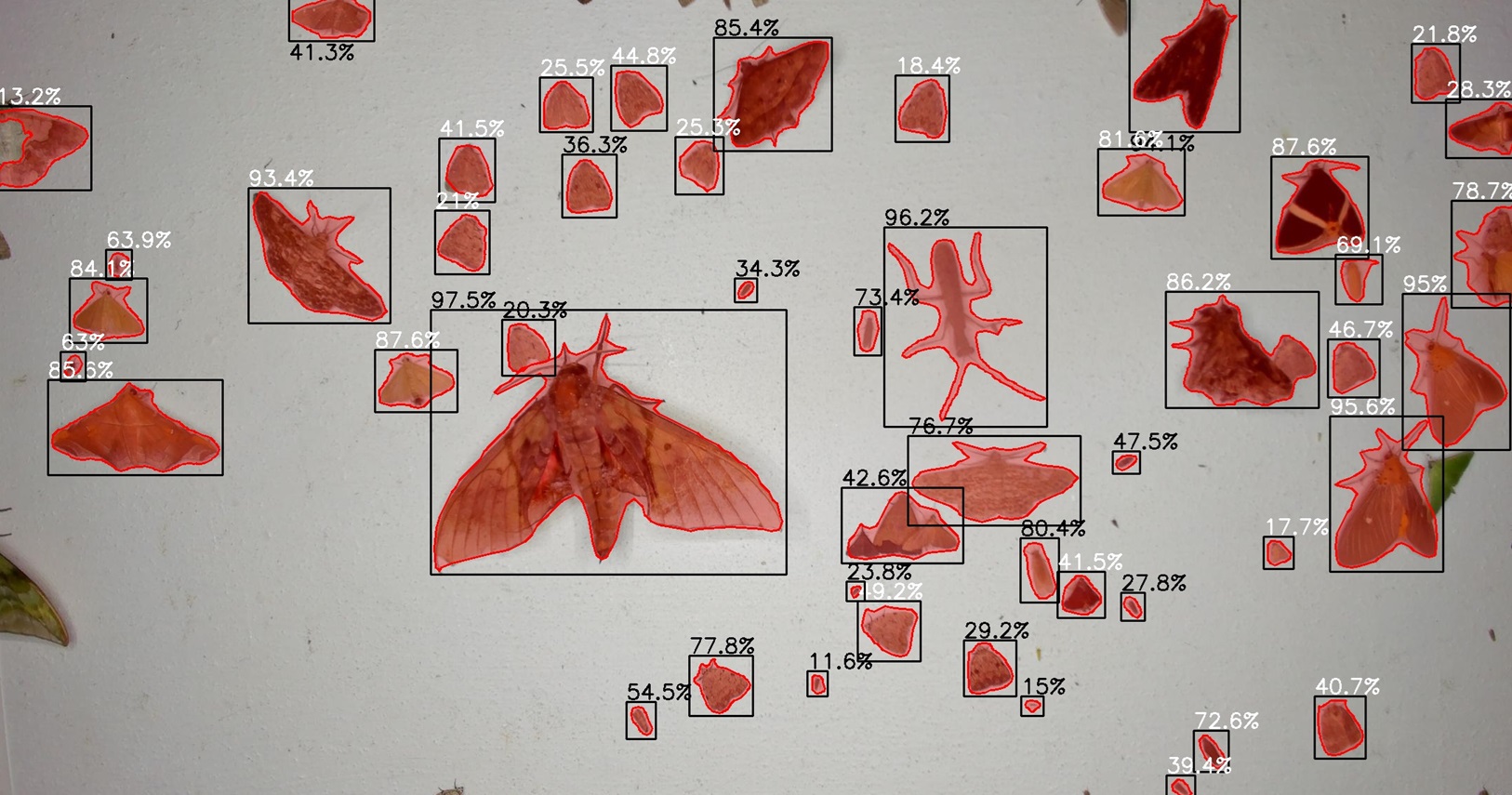
This tool identifies and localises insects in images and video recordings captured by camera traps. It focuses on pollinators in natural environments and integrates methods developed across several publications from the MAMBO project. It combines motion-informed object detection, colour and semantic segmentation, hierarchical classification across three taxonomic ranks, and tracking designed for low-framerate recordings. The system processes time-lapse images and video from various insect camera traps and supports both natural and artificial floral backgrounds. It generates detailed outputs, including CSV files with temporal, taxonomic, and spatial information, labeled videos, insect crop images, and track visualisations. In addition, it incorporates extensive annotated datasets and allows new taxa groups to be added for specific research needs.
Benefits of using the technology
The tool provides a unified and automated workflow that reduces manual annotation efforts by detecting, classifying, and tracking insects at multiple taxonomic levels. It enables detailed ecological analyses, including occupancy modelling, abundance assessments, phenology studies, and research on pollinator and plant interactions. Its ability to classify up to 80 taxa groups at genus or species level, combined with robust tracking and visualization, offers a high-resolution understanding of insect activity in diverse environments.
Target users
The tool is designed for entomologists, ecologists, and researchers working in biodiversity monitoring. It supports field studies that rely on camera trap imagery, including long-term ecological monitoring, habitat assessment, and plant-pollinator interaction analyses. It can also support projects that require detailed datasets for extending or refining insect classification models.
Read more
Sound recognition models
Description
Sound recognition models allowing to identify sound recordings to species level have been developed for European breeding birds, amphibians, bats and grasshoppers. Data used for training and testing these machine learning models is obtained from online open-access bioacoustics repositories, most notably Xeno-Canto.org. The models aim to contain all species found on the European continent; however, their taxonomic coverage is currently restricted by the availability of training data. For birds, all species are covered, whereas for the other groups some species found in southern or eastern Europe are not included as suitable training data is not yet available. The volume of available training data has increased dramatically in the past few years, partly as a result of activities within MAMBO. The models are intended to be updated annually with the most recent training data, which is expected to lead to a steady expansion of taxonomic coverage over the coming years.
The models allow analysis of sound recordings using three-second time windows, predicting presence or absence (with confidence information) for each window. The models will be available for download allowing them to be applied on local devices or being deployed for use in biodiversity portals or large-scale monitoring projects. The models can analyse sound recordings of any length in both WAV and MP3 format. They are not restricted to specific recording equipment and can process recordings from smartphones, relatively inexpensive devices (such as Audiomoths), as well as high-end equipment. The use is not restricted to monitoring and they can also be used as identification tools for citizen scientists. Detection and identification performance varies among species and, in addition, also depends on the quality of the recording. The models have been tested in the field using Audiomoths, which are relatively inexpensive devices capable of broadband recording, covering both the audible and ultrasonic ranges up to a sample rate of 384 kHz.
Benefits of using the tool
Many animal species can be most easily, or even primarily, detected through sound. Collecting sound recordings in the field allows to detect the presence of species and can even support the assessment of population trends. However, manually identifying species based on sound recordings is time-consuming work that requires substantial expertise. Sound recognition models can address this limitation by analysing large volumes of sound recordings with high efficiency.
An additional benefit is that the approach enables the collection of well-standardised data across multiple species groups using a single method. Combining passive acoustic monitoring (PAM) with automated species recognition can increase both the accuracy and the volume of ecological data while reducing costs. This results in a highly scalable method that supports standardised biodiversity monitoring on an international scale.
The sound recording models can be deployed both for the analysis of long-duration recordings and to provide identification support for citizen scientists. For the latter purpose, the models will be made available for use in biodiversity portals such as Observation.org and associated mobile apps. Users can opt to run the models locally on their own devices or to access them through an API, for instance through the ARISE infrastructure.
Long-duration recordings can be used for species inventories as well as for long-term monitoring. Such monitoring may rely on fixed recording devices deployed at a single location over extended periods (Passive Acoustic Monitoring, PAM) or on Audio Transect Walks (ATW) in which recordings are collected together with GPS data along a standardised transect.
Target users
The primary audience consists of professionals within the field of ecology and nature conservation; including Natura 2000 officers, reserve managers and consultants and NGOs involved in biodiversity monitoring. Academic researchers and students may also utilise the survey protocols and the machine learning pipeline for broader ecological questions.
Once the models are made available through biodiversity portals and apps, the user base can expand to include tens of thousands of volunteers actively engaged with recording biodiversity. In addition, the models may be applied in nature education, using sound-based identification to make citizens more aware of the species present in their surroundings.
Future development
Although models for all four mentioned species groups will be available from mid-2026 onwards, development work will continue. The models will be updated annually, allowing for the inclusion of additional species as new training data become available. To ensure broad accessibility for the thousands of citizen scientists, biodiversity portals and mobile apps will require modification; these updates are expected to take place in 2026 and 2027. With these improvements, the models can become a primary tool for audio-based biodiversity monitoring, supported by the development of standardised protocols over the coming years.
The sound recognition models for European animals make audio-based monitoring along transect possible
A great way to visualise sound is by means of a spectrogram. Here you can see that in the soundclip, there are multiple species present. The high-pitched calls have been made by a bat, and the lower part comprises three species of grasshoppers (Uromenus rugosicollis, Decticus albifrons, and Phaneroptera nana).
Read more
Plant Quadrat Image analysis tool
Description of the tool
Co-developed through the GUARDEN and MAMBO projects (notably within the framework of MAMBO WP3/T3.4 and presented in WP5), the plant species community identification tool transforms a simple photograph of a quadrat or habitat into a structured description of the plant community. A vertical image of a 50 × 50 cm plot is automatically tiled and analysed by a deep learning model covering several tens of thousands of species. The result is presented as a ranked list of probable species, accompanied by identification confidence scores. For transparency and validation purposes, the service can generate tiles indicating in the image where the signal of each species is strongest. A reject head filtering out tiles of non-higher plants (algae, mosses, lichens) or abiotic content (soil, rock) to reduce false detections is currently under development. Basic cover proxies (e.g., vegetation fraction by species) are computed to support condition measurements. The tool is available on the Pl@ntNet web platform for authorised Pl@ntNet user accounts (request access here: https://forms.gle/BYH7WC9d8eJEm3dk9), as well as via an API for seamless integration with national or institutional portals. Full documentation is provided at: https://docs.plantnet.org/en/beta/vegetation-surveys/
References :
Espitalier, V., Lombardo, J. C., Goëau, H., Botella, C., Høye, T. T., Dyrmann, M., ... & Joly, A. (2025). Adapting a global plant identification model to detect invasive alien plant species in high-resolution roadside images. Ecological Informatics, 103129. https://doi.org/10.1016/j.ecoinf.2025.103129
Martellucci, G., Goeau, H., Bonnet, P., Vinatier, F., & Joly, A. (2025). Overview of PlantCLEF 2025: Multi-species plant identification in vegetation quadrat images. arXiv preprint arXiv:2509.17602. https://doi.org/10.48550/arXiv.2509.17602
Benefits of using the Plant Quadrat Image analysis tool
The service delivers plot‑level results in seconds, turning a bottleneck (expert time spent transcribing and checking species lists) into a rapid, repeatable step that scales across sites and seasons. By enforcing a consistent pipeline and metadata standard, it improves comparability over time and between teams, while the visualisation of the tiles gives practitioners immediate, field‑ready feedback to correct issues before they propagate. Because the outputs are export‑ready (species list, confidences, coverage proxies), they can be reused for statutory reporting, trend analyses and restoration tracking without ad‑hoc preprocessing. Managers gain faster evidence for decisions such as adjusting grazing, moving or invasive control; researchers gain harmonised inputs for models; and portals gain semi‑automated validation flow that still leaves room for expert review where confidence is low. Integration with remote sensing workflows is currently being evaluated to eventually enable the analysis of canopy data or the study of vegetation structure on a large scale, thus providing reliable indicators of habitat status. The data generated via this tool is under a Creative Commons license, allowing teams to share the results as open data.
Target users
The primary audience is practitioners who need timely, standardised vegetation information at plot scale: reserve and site managers, Natura 2000 officers, public agencies and NGOs overseeing monitoring contracts, and consultants delivering habitat assessments. Academic ecologists and students can use the batch workflow to accelerate quadrat‑based surveys, document methods and reproduce analyses; training materials make it suitable for teaching modern monitoring. National biodiversity portals or research projects can embed the API to offer guided community identification for curated quadrat photo protocols, while citizen‑science coordinators can pilot structured, seasonal campaigns that complement expert surveys. SMEs and solution providers can integrate the service in field apps or dashboards to add AI‑assisted plant community features without building models from scratch. Finally, data engineers and modellers can exploit the FAIR‑aligned outputs to feed statistical or machine‑learning pipelines, or to fuse with remote‑sensing layers for habitat condition metrics.
Read more
Airborne laser scanning
Description
The product Airborne LiDAR for habitat condition monitoring comprises harmonised geospatial data products of vegetation structure derived from airborne laser scanning point clouds, generated at national and site-scales, including multiple countries and time periods (see overview: https://doi.org/10.3897/arphapreprints.e188540). Most of these products are underpinned by the Laserfarm workflow (https://doi.org/10.1016/j.ecoinf.2022.101836), which enables scalable, reproducible and cost-efficient processing of large LiDAR datasets into standardised vegetation structure metrics (e.g. canopy height, vegetation density, vertical complexity). Resulting datasets are made findable and accessible through established data portals, catalogues and digital repositories, supporting biodiversity monitoring, habitat assessment and policy reporting.
The main novelty lies in the combination of a scalable and efficient processing workflow (Laserfarm) with the production of harmonised, analysis-ready vegetation structure metrics at site- and national scale across multiple countries and time periods. This approach overcomes traditional barriers related to data volume, computational requirements and lack of standardisation, enabling repeatable and comparable habitat monitoring across regions.
Benefits of using it
Improved, consistent monitoring of habitat condition and structural diversity at large spatial scales
Enhanced evidence base for biodiversity assessments, conservation planning and environmental reporting
Support to EU and national policy frameworks (e.g. biodiversity strategies, habitat reporting)
Increased uptake of LiDAR-derived products by public authorities and research communities
Target users
Researchers, public authorities, environmental agencies, conservation practitioners, spatial planners, and private sector actors involved in environmental monitoring and ecosystem assessment. Examples:
National and regional environmental authorities
Biodiversity and ecosystem researchers
Conservation NGOs
Environmental consultancies and service providers
Copernicus and other Earth observation downstream users
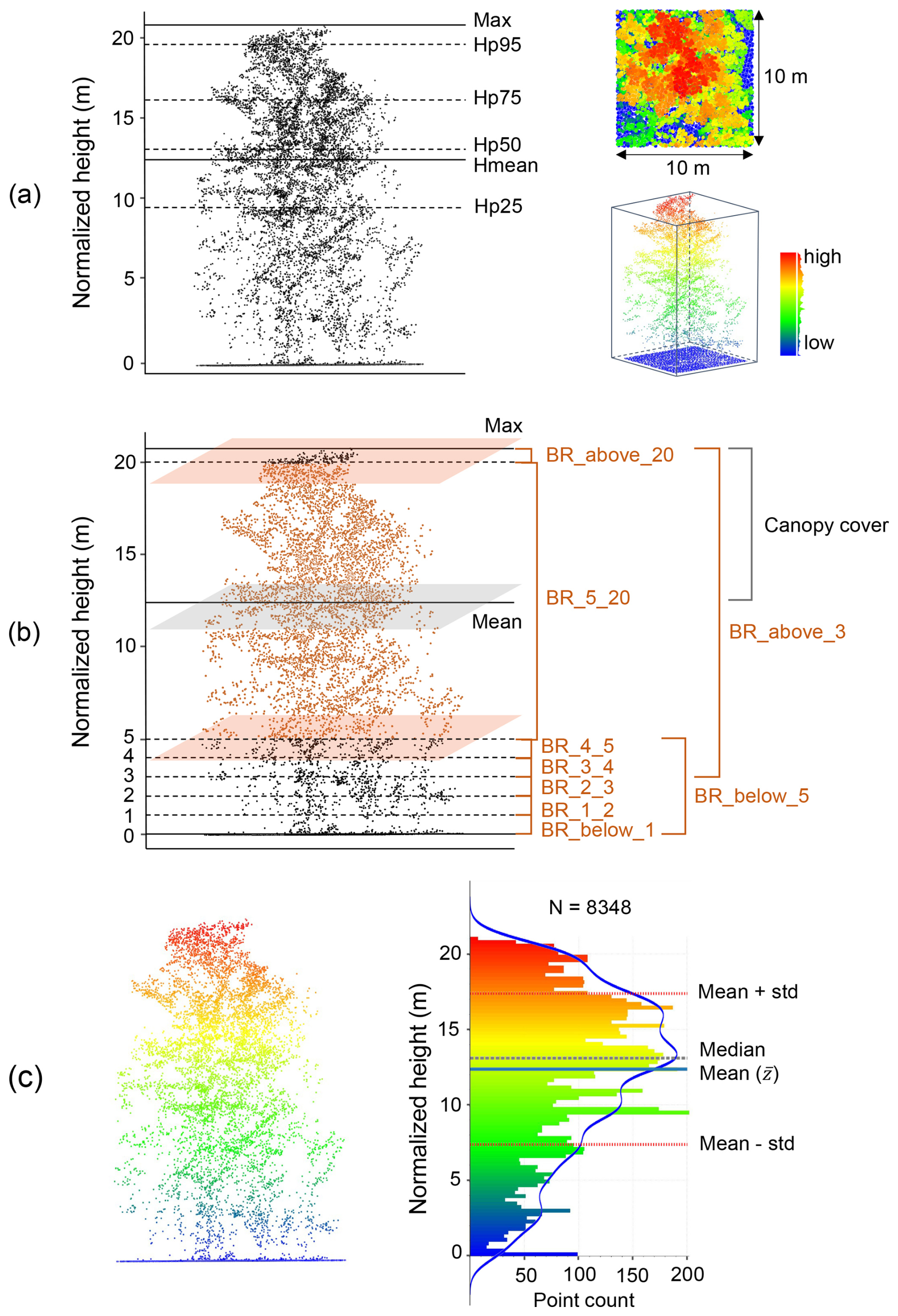
Examples of lidar metric generation in a 10 m × 10 m grid cell (the number of all points: N = 8348). (a) Metrics of vegetation height (mean, max, and percentiles of normalized height). (b) Vegetation cover metrics representing vegetation density within specific height layers (e.g. “BR_4_5” indicates the vegetation density between 4–5 m; feature name: “band_ratio_4_normalized_height_5”). (c) Metrics of vegetation structural variability (e.g. standard deviation and variance of vegetation height are calculated based on mean height ; kurtosis and skewness of vegetation height are calculated based on the standard deviation and mean height within a cell) (see detailed calculation formula in Table 3). The blue line in (c) represents a kernel density estimate (KDE) showing the shape of the point distribution. Adapted from Shi et al. (2025): https://doi.org/10.5194/essd-17-3641-2025
Read more
High-resolution species and habitat maps
Description of the tool
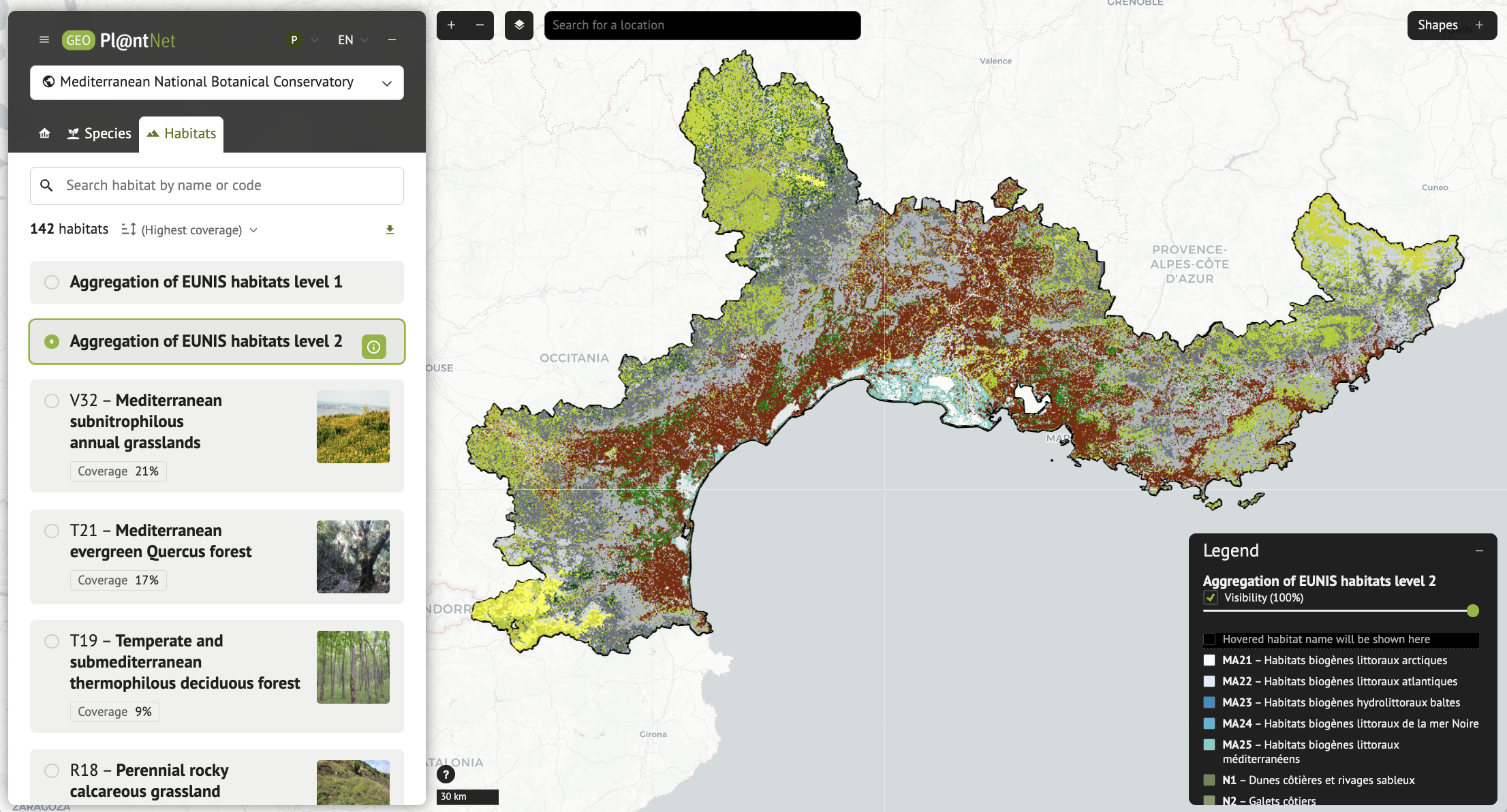
A new generation of very high-resolution (50×50 m) species and habitat maps available at European scale has been developed within the MAMBO project. Produced by Inria and CIRAD (Pl@ntNet consortium), these maps are generated by highly innovative AI models, combining multi-modal deep-learning models for large-scale species distribution modelling and a specialised large language model (Pl@ntBERT) for habitat inference from plant assemblages. They describe all plant species and EUNIS habitats with unprecedented spatial detail at continental scale. The maps are fully explorable online and directly downloadable as GeoTIFF files via GeoPl@ntNet, supporting conservation, environmental assessment, land-use planning and biodiversity research.
Benefits of using the technology
The primary benefit of this framework is its ability to overcome the logistical and financial barriers to large-scale habitat monitoring. By using a two-step AI approach, predicting local species assemblages and translating them into EUNIS habitat types via thePl@ntBert large language model, the tool provides:
High Resolution: It achieves a spatial granularity of 50m, which is essential for capturing the complex, mosaic-like nature of terrestrial habitats.
Scalability: This allows to consider future automated monitoring across entire regions where in situ surveying would be impossible.
Actionable Data: The outputs are available as "Cloud Optimized GeoTIFF" files and WMS streams, facilitating easy integration into GIS workflows for conservation planning.
Target users
The tool is designed for a variety of stakeholders involved in biodiversity monitoring and policy-making, including:
Conservation Practitioners & Protected Area Managers: For detailed assessment of habitat status within specific regions (e.g., National Parks).
Policy Makers & EU Agencies: To support reporting requirements under the EU Habitats Directive and to track progress toward biodiversity targets.
Researchers in Ecology & Informatics: For testing ecological hypotheses at large scales, and utilising high-resolution biodiversity data products.
Environmental Consultants: In the long term, this tool can support high-resolution biodiversity impact assessments and ecosystem monitoring.